Embedding(エンベディング)の概念を理解してみた
こんにちは、2年目新卒入社の開発チーム、近藤です。
近年ChatGPTの登場により、生成AIの注目度が急激に高まっています。
ChatGPTの注目度が上がった要因として、今までのチャットボットとはくらべものにならないほどに柔軟なやりとりができるようになったことが挙げられます。
自然言語をコンピュータで扱う自然言語処理(NLP)の分野は、GPTの使用により大きく進歩しました。
ここで紹介するのはEmbeddingという手法です。
自然言語処理におけるEmbeddingとは、単語や文といった自然言語の情報を、その単語や文の意味を表現するベクトル空間に配置することです。
配置することで、その位置関係から要素同士の関係性を数値で扱える様になり、検索エンジンやレコメンド機能、チャットボットなど様々なものに利用できます。
例えば検索エンジンで利用する場合、キーワード検索では、キーワードが含まれている文しか検索できませんが、キーワードの持つ意味で検索をすれば、近接する意味の単語を含む文も検索できます。
また、Embeddingは機械学習の分野では自然言語処理だけでなく、様々なケース(例えば画像認識)で利用されている方法です。
そのため、MLエンジニアになるにはEmbeddingがどんなものかしっかり理解しておく必要があります。
この記事ではEmbeddingの概念や、基礎を理解するため、例題として自動車のジオメトリや価格などの値を多次元空間にプロットすることを試してみます。

実験
データの作成
データは車選びドットコムに掲載されているカタログデータから、「車名、排気量、全長、全幅、全高、室内長、室内幅、室内高、乗車定員、ドア枚数、中古相場価格」を集計していきます。
車名,排気量,全長,全幅,全高,室内長, 室内幅, 室内高 ,乗車定員,ドア枚数,中古相場価格
"IS300h", 2500, 4680, 1810, 1430, 1945, 1500, 1170, 5,4, 234,
"RX450h", 2500, 4890, 1920, 1700, 1915, 1615, 1205, 5, 5, 471,
"NX300h", 2500, 4640, 1845, 1645, 2080, 1520, 1180, 5, 5, 392,
"プリウス", 2000, 4600, 1780, 1430, 1840, 1500, 1130, 5, 4, 155,
"アルファード", 2500, 4945, 1850, 1935, 3210, 1590, 1400, 8, 5, 369,
"パッソ", 1000, 3650, 1665, 1525, 1975, 1420, 1270, 5, 5, 80,
"セレナ", 2000, 4685, 1695, 1865, 3170, 1545, 1400, 8, 5, 207,
"ノート", 1200, 4045, 1695, 1505, 2030, 1445, 1240, 5, 5, 116,
"フェアレディZ", 3700, 4260, 1845, 1315, 990, 1495, 2, 2, 247,
"シビック", 1500, 4550, 1800, 1415, 1915, 1545, 1145, 5, 5, 262,
"CR-Z", 1500, 4105, 1740, 1395, 1605, 1430, 1080, 4, 2, 92,
"フィット", 1500, 3995, 1695, 1515, 1955, 1445, 1260, 5, 5, 119,
"ロードスター", 1500, 3915, 1735, 1245, 940, 1425, 1055, 2, 2, 197,
"CX-5", 2000, 4575, 1845, 1690, 1890, 1540, 1265, 5, 5, 217,
"RX-8", 2000, 4470, 1770, 1340, 1755, 1455, 1120, 4, 4, 117,
"サンバー", 660, 3395, 1475, 1890, 1915, 1270, 1250, 4, 5, 55,
"フォレスター", 2000, 4625, 1815, 1715, 2100, 1545, 1270, 5, 5, 195,
"BRZ", 2400, 4265, 1775, 1310, 1625, 1480, 1060, 4, 2, 228,
"エブリイ", 660, 3395, 1475, 1895, 1820, 1280, 1240, 4, 5, 92,
"ソリオ", 1200, 3790, 1645, 1745, 2500, 1420, 1365, 5, 5, 102,
"ジムニー", 660, 3395, 1475, 1725, 1770, 1300, 1200, 4, 3, 139,
"ムーブ" 660, 3395, 1475, 1630, 2080, 1320, 1280, 4,5, 70,
"タント", 660, 3395, 1475, 1755, 2125, 1350, 1370, 4, 5, 90,
"ミラ" 660, 3395, 1475, 1530, 2000, 1350, 1265, 4, 5, 27,
"アウトランダー", 2000, 4695, 1810, 1710, 2580, 1495, 1265, 7, 5, 266,
"デリカD5", 2000, 4790, 1795, 1850, 2915, 1505, 1310, 8, 5, 298,
"パジェロ", 3000, 4900, 1875, 1870, 2535, 1525, 1235, 7, 5, 200,Embeddingする
データの用意ができたらEmbeddingします。
今回は、Embeddingの全体像を把握することを目的としているため、凝った方法は採用せず、車種の各データを単純に0-1の範囲に収まる様に正規化してみます。
計算式は、(ある車種の数値 – 最小値) / (最大値- 最小値) となります。
例えば、プリウス排気量の場合は、「排気量2000㏄、リストの最小値が660cc、最大値が3700㏄」なので、プリウスの排気量は (2000 – 660) / (3700 – 660)=0.440 となります。
ここでは、基本的な車両情報である「排気量、全長、全幅、全高、室内長、室内幅、室内高、乗車定員、ドア枚数」の9項目を使用します。(中古相場価格は後ほど使用します)
グラフにマッピング(可視化)する
Embeddingされたデータをマッピングしてみましょう。
多次元のベクトルを、主成分分析(PCA)で次元圧縮して2次元に落とし込んで可視化します。
主成分分析とは、たくさんの変数の情報をできるだけ損なわずに少ない変数に置き換えることで、人間がデータの相関関係などを理解しやすくするために使用されます。
必要に応じて、モジュールをインストールしてください。
※matplotlibが文字化けするため、japanize_matplotlibモジュールを使用
import numpy as np
from sklearn.decomposition import PCA
import japanize_matplotlib
import matplotlib.pyplot as plt
car_names = ["IS300h", "RX450h", "NX300h",
"プリウス", "アルファード", "パッソ",
"セレナ", "ノート", "フェアレディZ",
"シビック", "CR-Z", "フィット",
"ロードスター", "CX-5", "RX-8",
"サンバー", "フォレスター", "BRZ",
"エブリイ", "ソリオ", "ジムニー",
"ムーヴ", "タント", "ミラ",
"アウトランダー", "デリカD5", "パジェロ"]
car_vec = [[0.605,0.829,0.752,0.268,0.442,0.666,0.333,0.5,0.666],
[0.605,0.964,1,0.659,0.429,1,0.434,0.5,1],
[0.605,0.803,0.831,0.579,0.502,0.724,0.362,0.5,1],
[0.440,0.777,0.685,0.268,0.396,0.666,0.217,0.5,0.666],
[0.605,1,0.842,1,1,0.927,1,1,1],
[0.111,0.164,0.426,0.405,0.455,0.434,0.623,0.5,1],
[0.440,0.832,0.494,0.898,0.982,0.797,1,1,1],
[0.177,0.419,0.494,0.376,0.480,0.507,0.536,0.5,1],
[1,0.558,0.831,0.101,0.022,0.652,0.101,0,0],
[0.276,0.745,0.730,0.246,0.429,0.797,0.260,0.5,1],
[0.276,0.458,0.595,0.217,0.292,0.463,0.072,0.333,0],
[0.276,0.387,0.494,0.391,0.447,0.507,0.594,0.5,1],
[0.276,0.335,0.584,0,0,0.449,0,0,0],
[0.440,0.761,0.831,0.644,0.418,0.782,0.608,0.5,1],
[0.440,0.693,0.662,0.137,0.359,0.536,0.188,0.333,0.666],
[0,0,0,0.934,0.429,0,0.565,0.333,1],
[0.440,0.793,0.764,0.681,0.511,0.797,0.623,0.5,1],
[0.572,0.561,0.674,0.094,0.301,0.608,0.014,0.333,0],
[0,0,0,0.942,0.387,0.028,0.536,0.333,1],
[0.177,0.254,0.382,0.724,0.687,0.434,0.898,0.5,1],
[0,0,0,0.695,0.365,0.086,0.420,0.333,0.333],
[0,0,0,0.557,0.502,0.144,0.652,0.333,1],
[0,0,0,0.739,0.522,0.231,0.913,0.333,1],
[0,0,0,0.413,0.466,0.231,0.608,0.333,1],
[0.440,0.838,0.752,0.673,0.722,0.652,0.608,0.833,1],
[0.440,0.9,0.719,0.876,0.870,0.681,0.739,1,1],
[0.769,0.970,0.898,0.905,0.702,0.739,0.52,0.833,1]]
car_vec = np.array(car_vec)
car_list=[]
vec_list=[]
for word in car_names:
car_list.append(word)
for vec in car_vec:
vec_list.append(vec)
# グラフ作成
pca = PCA(n_components=2)
pca_vec_list = pca.fit_transform(vec_list)
X = pca_vec_list[:,0]
Y = pca_vec_list[:,1]
plt.figure(figsize=(12, 12))
plt.rcParams["font.size"] = 15
plt.scatter(X,Y,s=10)
for i,(x_name,y_name) in enumerate(zip(X,Y)):
plt.annotate(car_list[i],(x_name,y_name))
plt.show()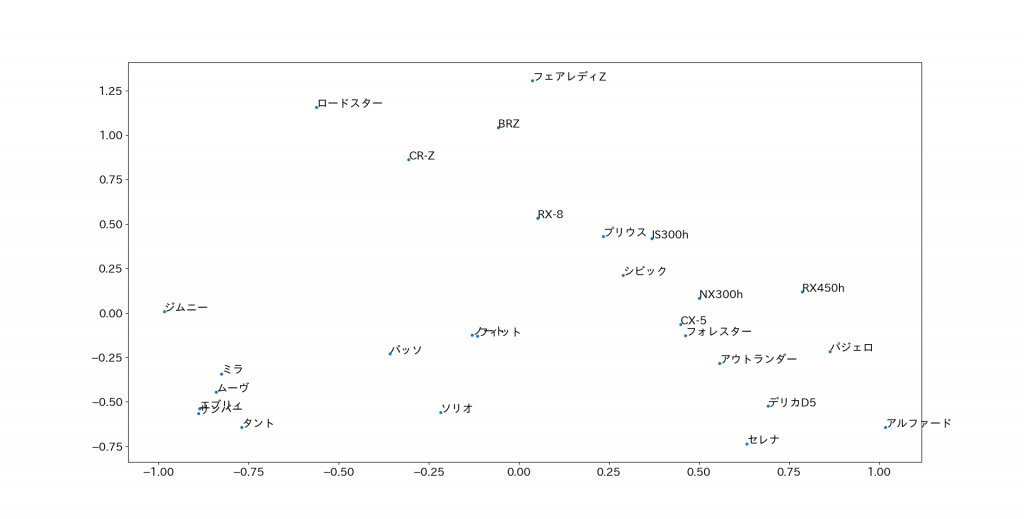
国産メーカーの車27種が2次元にプロットされました。
車の形状データをEmbeddingしていますので、似た形状を持っている車種のクラスターができていることがわかります。例えば、軽自動車は左下に、ミニバンは右下の方に集まっています。
ジムニーは他の軽自動車と比べて、ドア枚数が少ない、定員が少ない、室内幅が短いなど少し尖ったスペックになっているので、少し離れた位置にプロットされています。
次元数を追加する
車の特徴の項目を、新たに「中古車金額の相場」を追加し同様に実験します。「中古車金額の相場」を追加することによって、車種の人気度や希少価値がグラフに影響を与えるはずです。
「排気量、全長、全幅、全高、室内長、室内幅、室内高、乗車定員、ドア枚数、中古相場価格」の10次元になります。
以下のデータをembeddingしたのち、同様にして実行すると、以下のような結果が得られました。
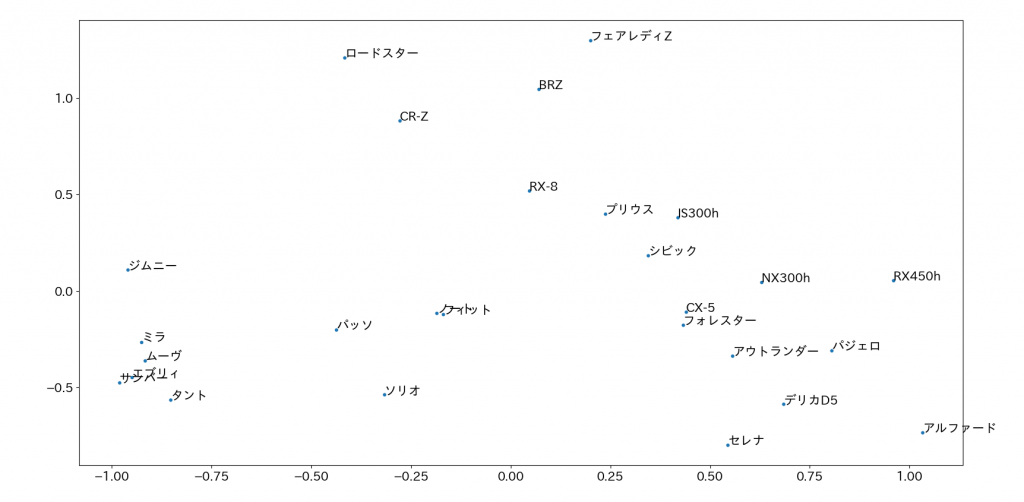
9次元のときと似た結果が得られました。図の上部をみると、9次元の時は、フェアレディZとRX-8がほぼ縦軸上に並んでいましたが、フェアレディZが大きく右にずれています。これは中古相場価格の次元が追加されたものであると考えられます。
また、左下の軽自動車を見ると、軽自動車は安価な車種が多く、ほぼ変わらない結果となりました。
他には、レクサスの3車種が右にずれたこと。フォレスターがCX-5より左に移動したことが分かります。
全体的に、中古車相場金額が追加されたことによって、高価な車両が右の方に寄っていることが分かります。
このように、車両情報と金額でEmbeddingすると、車種の特徴や人気具合の違いが距離に現れました。
まとめ
近年注目される生成AIの技術の中で、Embeddingという手法が重要な役割を果たしています。
これは、単語や文といった自然言語をベクトル空間に配置し、その位置関係から要素間の関係性を数値化するものです。
これにより、検索エンジンやチャットボットなどが柔軟な対話を実現できるようになりました。
Embeddingは機械学習の基本的な手法でもあり、MLエンジニアにとって理解しておくべき知識です。
Embeddingの概念や、基礎を理解するための実験として、自動車の特性をEmbeddingして分析した結果、車種の形状や価格などの情報を視覚的に理解することができました。
この記事が皆さんの理解の助けになれたらよいなと思っています。
参考サイト
- OpenAI API 「Embeddings」
- Hugging Face「Getting Started With Embeddings」
- Google Cloud 公式ブログ「AI のマルチツールのご紹介: ベクトル エンベディング 」
- Cloud アーキテクチャ センター「概要: 機械学習のための特徴埋め込みの抽出と提供」
- 車選びドットコム「自動車カタログ」
ファブリカコミュニケーションズで働いてみませんか?
あったらいいな、をカタチに。人々を幸せにする革新的なサービスを、私たちと一緒に創っていくメンバーを募集しています。
ファブリカコミュニケーションズの社員は「全員がクリエイター」。アイデアの発信に社歴や部署の垣根はありません。
“自分から発信できる人に、どんどんチャンスが与えられる“そんな環境で活躍してみませんか?ご興味のある方は、以下の採用ページをご覧ください。