【開発者必見】アプリケーション開発で大量のテストデータを作る方法
アプリケーション開発において、負荷テストやインデックスの効果を検証するためには、大量のテストデータが必要になります。
テストに必要な件数は、開発するサービスの内容により異なり、まずは想定されるデータ量を算出するところから始めます。
例えば、1日200件のデータ登録が見込まれるサービスの場合、10年間使用することを想定すると76万件となり、100万件ほどのテストデータが必要となります。
やり方を間違えると、非常に多くの時間がかかりますので、今回はどのような手法を使えば、大量のテストデータを効率よく作成できるかをこれから検証していきたいと思います。
環境
- CentOS7(Windows10にVirtualBoxで仮想環境を構築)
- MySQL5.7
事前準備
今回はサンプルとして、下記の受注トランを作ることにします。
下記のSQL文を実行してください。
CREATE TABLE orders (
id INT NOT NULL AUTO_INCREMENT,
order_date date,
customer_id int,
product_id int,
order_quantity int,
unit_price int,
sales_staff_id int,
create_time datetime,
update_time datetime,
delete_time datetime,
create_staff_id int,
update_staff_id int,
delete_staff_id int,
PRIMARY KEY (id)
) DEFAULT CHARSET=utf8;
データ作成
データを作成する方法は色々とありますが、今回はその中でもDB(MySQL)の持つ機能を利用した次の3つの方法で行うこととしました。また、合わせて私の主観ではありますが、それぞれの方法についてメリットとデメリットを記載します。
1.INSERT文 + UPDATE文を利用して作成
INSERT SELECT文で空のレコードを増幅させ、全データINSERT後にUPDATE文で後からカラムの値を変更する。
(1)ファイルを作成 全てのSQL文を纏めて記載
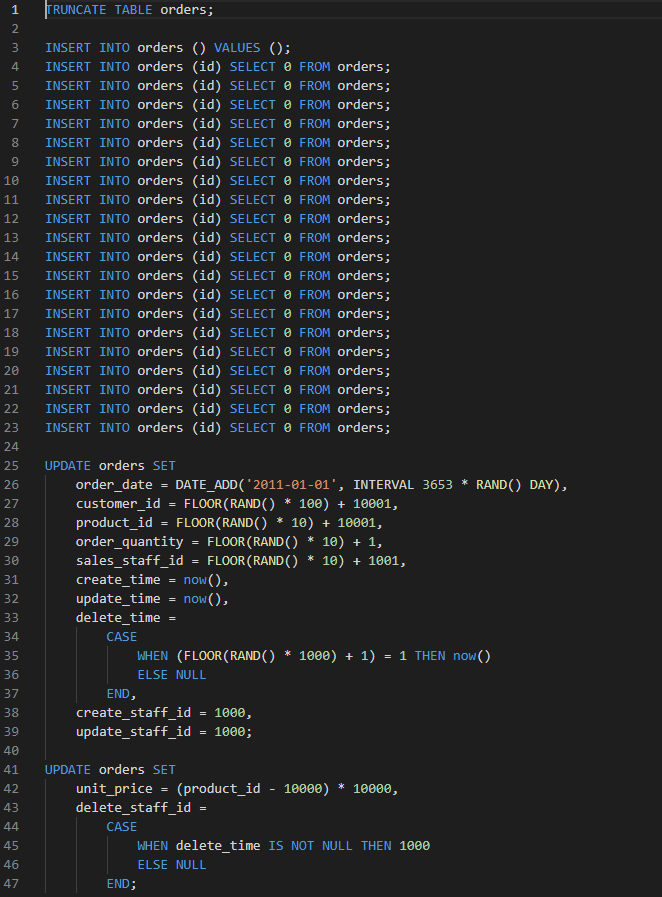
- INSERT文で空のレコードを1件作成
- INSERT SELECT文で、レコードを倍々に増幅させる20回実行すると、100万件超(1,048,576件)となります
- UPDATE文で定義した値に一括更新
(2)ファイルを実行
$ mysql -u root -p demo < work/insert_orders_type1.sql
処理時間:57.5秒
mysql> SELECT count★ FROM orders;
+----------+
| count★ |
+----------+
| 1048576 |
+----------+
1 row in set (0.31 sec) <メリット>
- INSERT UPDATE文だけで実装できるので、比較的簡単に対応できる
- 全てのSQL文を1つのファイルを纏めてしまえば、ファイル実行
<デメリット>
- 他の方法と比較して、時間がかかる
2.LOAD DATA INFILEを利用して作成
EXCELでデータを作成し、CSVで出力してDBにインポートを行います。
※Excel2007以降のバージョンは、1,048,576行のデータが扱えますが、Excel2003までバージョンは65,536行までしか扱えません
(1)EXCELで100万件のデータを作成
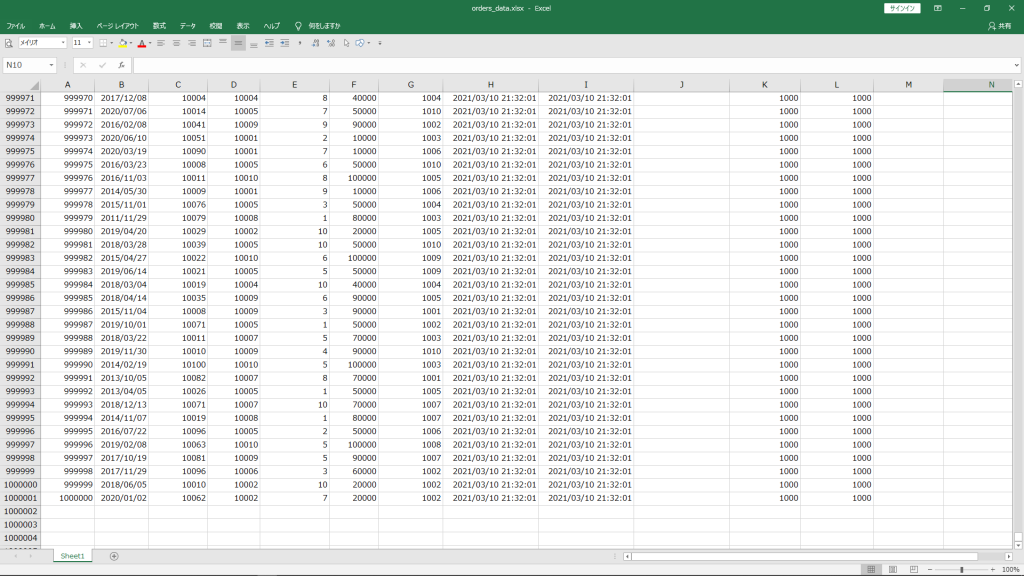
(2)EXCELからCSV出力
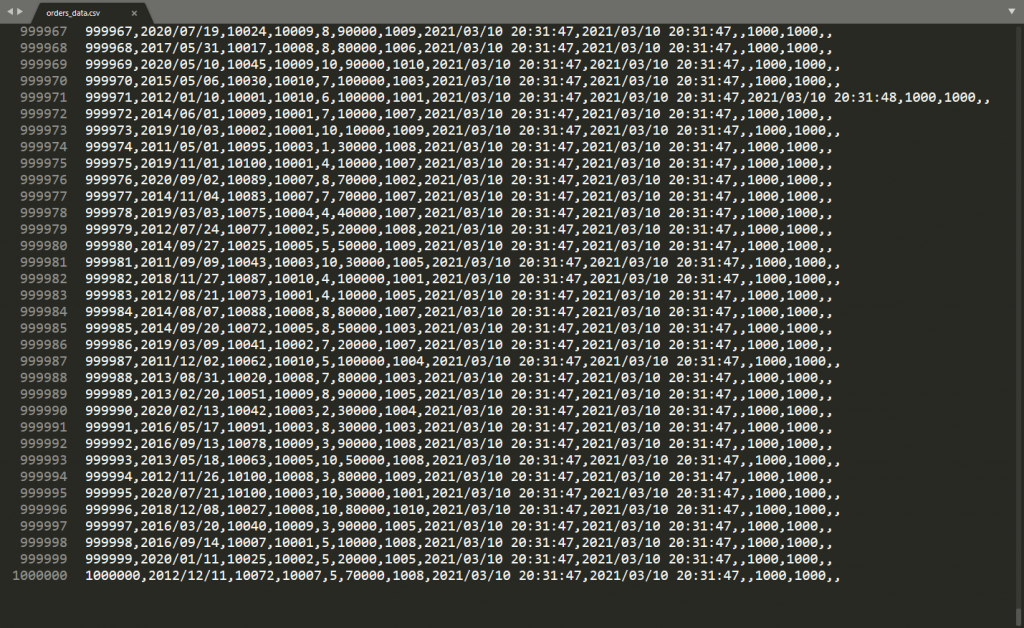
(3)DBにデータ登録
mysql> LOAD DATA LOCAL INFILE '/home/cic/work/orders_data.csv' INTO TABLE orders FIELDS TERMINATED BY ',';
Query OK, 1000000 rows affected, 65535 warnings (9.36 sec)
Records: 1000000 Deleted: 0 Skipped: 0 Warnings: 2990003速っ!10秒かからない!
<メリット>
- 直感的にデータを作成できる
- 処理が速い
<デメリット>
- EXCELで大量にデータを作る際、動作が重くなりフリーズする可能性があるので、低スペックのPCを使用する場合は注意が必要
(※1万件ほどのデータを作成するのであれば、手軽にできるので良いのではないかと思います)
3.ストアドプロシージャーを利用して作成
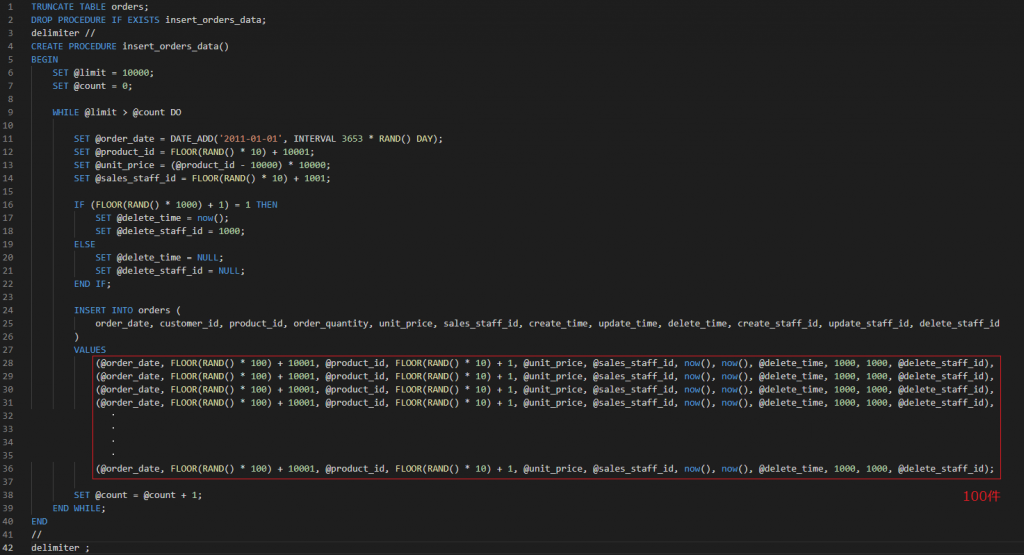
(1)ストアドプロシージャーを作成
バルクインサートを利用して、1回でコミットする件数を多くする。試しに①と②のパターンで比較してみました。
①1回のコミットを100件にして、1万回ループした場合
② 1回のコミットを10件にして、10万回ループした場合
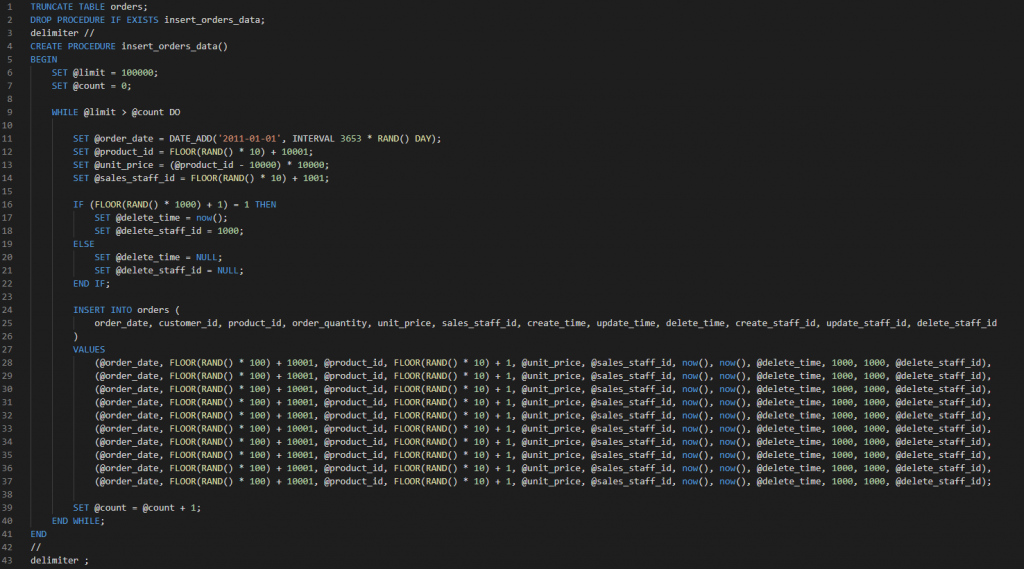
(2)ストアドプロシージャーを実行
1回でコミットする件数を多くした①のほうが②よりも4倍以上速い
① 1回のコミットを100件にして、1万回ループした場合
mysql> CALL insert_orders_data;
Query OK, 0 rows affected (29.60 sec)
mysql> SELECT count★ FROM orders;
+----------+
| count★ |
+----------+
| 1000000 |
+----------+
1 row in set (0.28 sec)
② 1回のコミットを10件にして、10万回ループした場合
mysql> CALL insert_orders_data;
Query OK, 0 rows affected (2 min 7.79 sec)
mysql> SELECT count★ FROM orders;
+----------+
| count★ |
+----------+
| 1000000 |
+----------+
1 row in set (0.26 sec)
<メリット>
- SQL単体だけではできないような処理や複数のテーブルが複雑に絡み合うような処理を実行することができる
- ストアドプロシージャーを実行時にパラメータを渡すことができる
(※今回のレベルのものであれば、ストアドプロシージャーを使う恩恵はそんなに感じられません)
<デメリット>
- ストアドプロシージャーでのプログラミング知識が必要
まとめ
これまでテストデータの作成は、PHPからSQL文を実行するようなプログラムを書いていましたが、DBの機能だけでも容易に実装できることが分かったことと、無駄なIOがなくなるので高速で実行できることを実感できました。
今回のような100万ほどのテストデータを作成するのには、1つ目の「INSERT文 + UPDATE文を利用して作成」が、
1万件ほどのデータで、EXCELがフリーズするリスクが低いものであれば、2つ目の「LOAD DATA INFILEを利用して作成」が良いのではないかと思います。
ファブリカコミュニケーションズで働いてみませんか?
あったらいいな、をカタチに。人々を幸せにする革新的なサービスを、私たちと一緒に創っていくメンバーを募集しています。
ファブリカコミュニケーションズの社員は「全員がクリエイター」。アイデアの発信に社歴や部署の垣根はありません。
“自分から発信できる人に、どんどんチャンスが与えられる“そんな環境で活躍してみませんか?ご興味のある方は、以下の採用ページをご覧ください。