AWS LambdaとElemental MediaConvertで自動動画変換
ひょんな事から、大量の動画ファイルを指定サイズのmp4形式の動画に変換する必要が出てきました。
普段なら、愛機(FreeBSD)に動画を放り込んでffmpegでガシガシと変換するところなんですが、何となく面白くないのでAWSでやってみるかと思い立ちました。
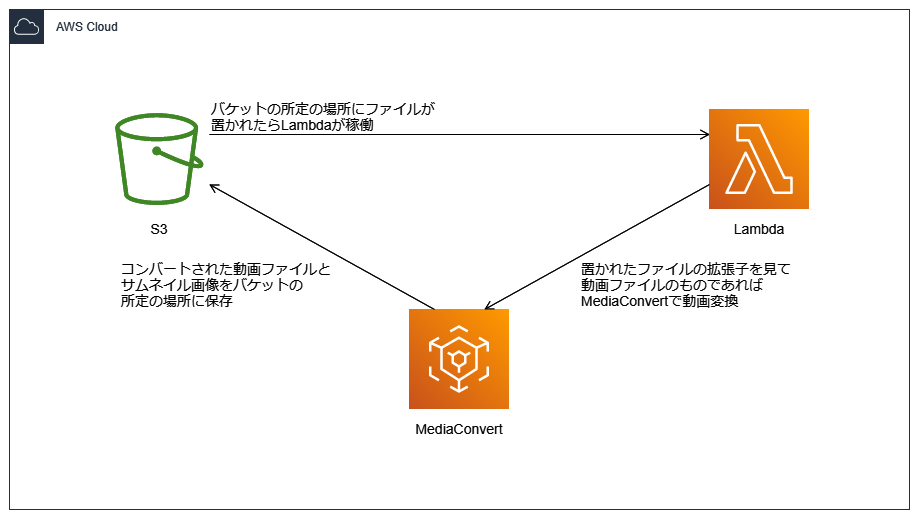
AWSにはElemental MediaConvertという動画変換サービスがあるので、S3とLambdaと連動させて変換する仕組みを作ります。
こんなイメージです。
では、さっそく作っていきましょう。
S3
ap-northeast-1(東京)リージョンに「mymoviebucket」というバケットを作成し、アップロード用に「Upload」、変換した動画ファイル保存用に「Convert」というフォルダを作成します。
今回はそのまま配信するようなこととかは考えていないので、アクセス許可はパブリックアクセスをすべてブロックするようにしてあります。
Elemental MediaConvert
まずはジョブテンプレートを作成します。
「入力」と「出力グループ」を追加します。
出力グループの追加時に選択肢が出ますが、単純にmp4形式の動画への変換のみなので「ファイルグループ」を選択しておきます。
送信先は、先ほどs3に作成したmymoviebucketバケットのConvertフォルダを指定します。出力する動画のビデオコーデックは「MPEG-4 AVC (H.264)」、解像度は要求として指定されていた「1280×720」、最大ビットレートは「4096000」にしておきます。
ついでにサムネイル用のスナップショットも作ってみようと思います。もう1つ「出力グループ」をファイルグループで追加します。
送信先は同じくConvertフォルダを指定、コンテナは「コンテナなし」を選択します。ビデオコーデックは「JPEG へのフレームキャプチャ」、解像度は先程と同じ「1280×720」、質(Quality)は「80」、フレームレートは「1/5」、最大キャプチャは「1」としておきます。サムネイルに音声は不要なのでオーディオは削除しておきます。
テンプレートが作成できたらJSONをエクスポートしておきます。(このJSONは後で使います)
ここで一度動画の変換をしておきます。ジョブテンプレートからジョブを作成します。
適当な動画ファイルをs3にアップロードして入力ファイルとして選択しジョブを作成してみると、以下のようなエラーが出てしまいます。
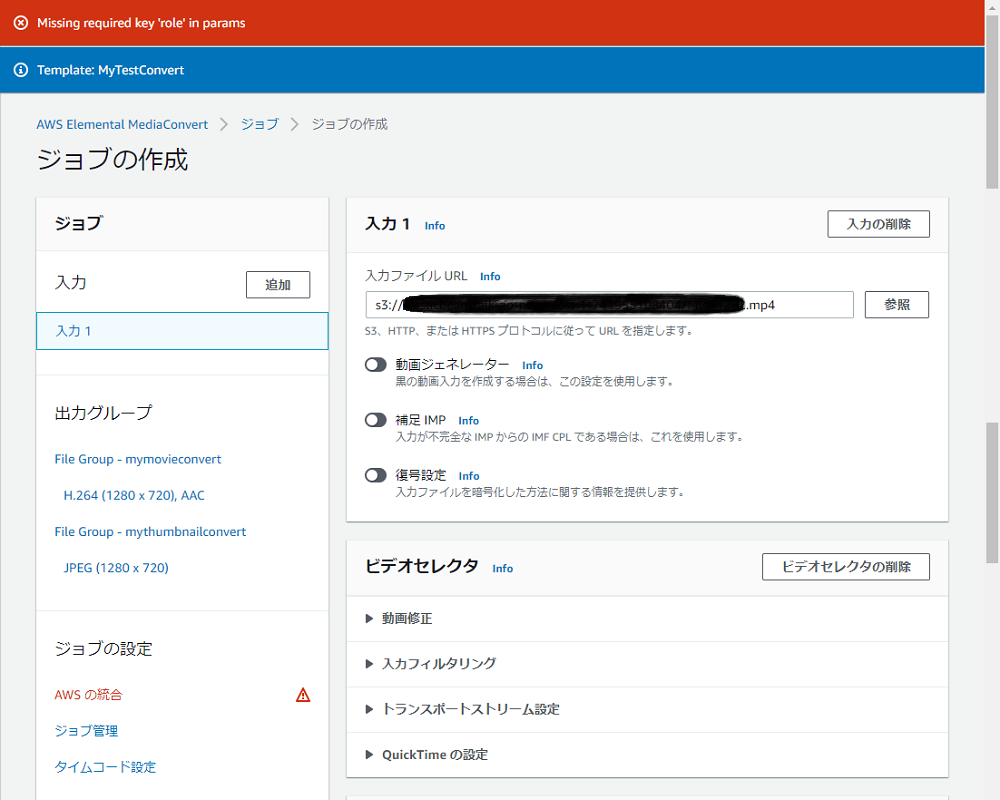
どうやらMediaConvertで変換するには専用のロールが必要らしいです。
左カラムの「AWSの統合」にアラートが出ていて、そこからサービスロールが作成できるので作っておきましょう。サービスロールの作成ができると動画が変換され、Convertフォルダに変換された動画ファイルとスナップショットの画像が保存されています。
Lambda
Uploadフォルダに動画ファイルが置かれた際に動作するLambda関数を作成します。
と、その前に。レイヤーを作成して、動画ファイルの情報を取得するためのffmpegを入れておきましょう。
下記公式URLに記載されているffmpegをダウンロード&展開してバイナリだけ取り出し、zipして先ほど作成したs3バケットあたりにアップロードしてオブジェクトURLをメモしておきます。
Processing user-generated content using AWS Lambda and FFmpeg | AWS Media Blog
https://aws.amazon.com/jp/blogs/media/processing-user-generated-content-using-aws-lambda-and-ffmpeg/
$ mkdir -p ffmpeg/bin
$ wget https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-amd64-static.tar.xz
$ tar xvfJ ffmpeg-release-amd64-static.tar.xz
$ cp ffmpeg-*-static/ffmpeg ffmpeg/bin/
$ cd ffmpeg$ zip -r ../ffmpeg.zip .レイヤーの作成で、ファイルは先程メモしたオブジェクトURLを指定します。
今回のLambda関数はPython3.9で作成するので、互換性のあるランタイムも同じものを選択しておきます。
では、改めて関数の作成です。
関数名は「mymovieconvert」としておきます。
ランタイムは「Python3.9」を選択します。
実行ロールは「基本的な Lambda アクセス権限で新しいロールを作成」で作成しておいて、後から修正します。
関数が作成できたら、先ほど作成したレイヤーを追加しておきましょう。
Lambda用IAMロール
関数の作成時につくられたロール「movieconvert-role-xxxxxxxx」には同じタイミングで作られたカスタムポリシーが登録されていますが、実はこれでは今回の仕組みを動かすには最低限、以下の2つの権限が不足しています。
- MediaConvertのジョブの実行
- S3の読み書き
こんな感じのポリシーを追加しておきます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "mediaconvert:CreateJob",
"Resource": "*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": "arn:aws:s3:::mymoviebucket/*"
},
{
"Sid": "VisualEditor2",
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:CreateLogGroup",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}Lambda関数のトリガー
Uploadフォルダにファイルが置かれたら動作するようにします。
トリガーの追加でソースにs3、バケットに作成したmymoviebucketを指定し、Prefixにはアップロードするフォルダ名の「Upload/」を指定します。
Lambda関数の設定調整
ffmpegやMediaConvertの処理でメモリを多く使ったり処理が長くなったりするので、以下の設定を変更しておきます。
- メモリを128MBから1024MBに
- タイムアウトを3秒から1分に
Lambdaのソースコード
ようやくソースコードです。
MediaConvertでジョブテンプレートのJSONを出力しましたが、ここで利用しています。テンプレートの設定を上書きしたいところだけ抜き出しています。
import json
import logging
import os
import boto3
import shlex
import subprocess
import re
SIGNED_URL_TIMEOUT = 60
MOVIE_EXT = ['mp4', 'avi', 'wmv']
WIDTH_MAX=1280
HEIGHT_MAX=720
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
# バケット名
s3_source_bucket = event['Records'][0]['s3']['bucket']['name']
# アップロードされたファイルのパス(Upload/foobar.mp4等)
s3_source_key = event['Records'][0]['s3']['object']['key']
# ファイル名から拡張子を除去したもの(hoge)と拡張子(mp4等)
s3_source_basename, s3_source_ext = os.path.splitext(s3_source_key)
s3_source_ext = s3_source_ext.replace('.', '')
# アップロードされたファイルの拡張子がMOVIE_EXTに含まれていなければ終了
# 大文字と小文字の判別とかは割愛
if s3_source_ext not in MOVIE_EXT:
logger.info(s3_source_key + 'は動画ではありません')
return {
'statusCode': 200
}
s3_client = boto3.client('s3')
# S3の署名付きURL
s3_source_signed_url = s3_client.generate_presigned_url('get_object',
Params={'Bucket': s3_source_bucket,
'Key': s3_source_key
},
ExpiresIn=SIGNED_URL_TIMEOUT
)
# 動画の情報取得
# p_movieinfo.stderrに「ffmpeg -i」の結果が入ってくる
# 出力された動画の情報がUTF-8だったりShiftJISだったりしたのでちょっと小細工してる
# (もっといい方法あるかなぁ)
ffmpeg_cmd = "/opt/bin/ffmpeg -i \"" + s3_source_signed_url + "\""
command_movieinfo = shlex.split(ffmpeg_cmd)
try:
p_movieinfo = subprocess.run(command_movieinfo, encoding='cp932', stdout=subprocess.PIPE, stderr=subprocess.PIPE)
movieinfo = p_movieinfo.stderr
do_command = 'try'
except:
p_movieinfo = subprocess.run(command_movieinfo, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
movieinfo = p_movieinfo.stderr.decode('utf-8')
do_command = 'except'
# 動画のWidthとHeightを取得
tmp = re.search("Stream [^\r\n]+ Video: [^\r\n]+, ([0-9]+)x([0-9]+),* ", movieinfo)
movie_width = int(tmp.group(1))
movie_height = int(tmp.group(2))
# アップロードされた動画のWidth、Height...
# 既定値以上→変換処理
# 既定値未満→そのままS3のConvertフォルダにコピー
if movie_width < WIDTH_MAX and movie_height < HEIGHT_MAX:
# S3のConvertフォルダにコピー
copy_to = re.sub(r'^Upload', 'Convert', s3_source_key)
copy_client = boto3.client('s3')
copy_client.copy_object(
Bucket=s3_source_bucket,
Key=copy_to,
CopySource={'Bucket': s3_source_bucket, 'Key': s3_source_key}
)
else:
# 変換処理
convert_client = boto3.client('mediaconvert', endpoint_url = 'https://*********.mediaconvert.ap-northeast-1.amazonaws.com')
result = convert_client.create_job(
Role = 'arn:aws:iam::************:role/service-role/MediaConvert_Default_Role',
JobTemplate = 'MyMovieConvertTemplate',
Settings = config_convert(s3_source_bucket, s3_source_key, WIDTH_MAX, HEIGHT_MAX)
)
# TODO implement
return {
'statusCode': 200
}
def config_convert(bucket, key, width, height):
return \
{
"OutputGroups": [
{
"CustomName": "MyMovieOutput",
"Outputs": [
{
"VideoDescription": {
"Width": width,
"Height": height
}
}
]
},
{
"CustomName": "MyThumbnailOutput",
"Outputs": [
{
"VideoDescription": {
"Width": width,
"Height": height,
"CodecSettings": {
"FrameCaptureSettings": {
"FramerateNumerator": 1,
"FramerateDenominator": 1,
"MaxCaptures": 5,
"Quality": 80
}
}
}
}
]
}
],
"Inputs": [
{
"FileInput": "s3://" + bucket + "/" + key
}
]
}これで全て完了です。
Uploadフォルダに動画ファイルをアップロードして暫く待つとConvertフォルダに変換された動画ファイルとスナップショットの画像(今回の指定だと1秒毎に1フレームをキャプチャして5枚)が保存されます。
今後の課題
アップロードされたファイルが動画かどうかを拡張子だけで判断していたり、16:9以外の解像度を考慮していなかったりなど、改善すべきポイントはまだまだあります。これを叩き台にしてブラッシュアップしていこうと思います。
ファブリカコミュニケーションズで働いてみませんか?
あったらいいな、をカタチに。人々を幸せにする革新的なサービスを、私たちと一緒に創っていくメンバーを募集しています。
ファブリカコミュニケーションズの社員は「全員がクリエイター」。アイデアの発信に社歴や部署の垣根はありません。
“自分から発信できる人に、どんどんチャンスが与えられる“そんな環境で活躍してみませんか?ご興味のある方は、以下の採用ページをご覧ください。