LinuxのcurlコマンドでID/パスワードのあるサイトに自動ログインしてみた♪~github編~

概要
昨今、お仕事でもプライベートでも、インターネット社会となった今、色々なサイトでパスワードを入力してログインする機会が増えました。
このあたり自動化などで定期的な情報取得や一括更新したいな~と思ったときでも、そのサイトがAPIを公開していなかったりして、自動化を断念する場合が多々あります。
そこで、今回は、ちょっとハック的(いや、大したことはやってないですが(笑))に、ID・パスワードでログインするようなサイトに自動ログインして、サイト内の情報取得や更新など、簡易的に自動化とかできるようにする基本手順を示してみたいと思います。
ここでは例として、github.comにcurlコマンドでログインする手順を紹介します。
※過度なアクセス・ログイン失敗などは不正アクセスと判断される場合がありますのでご留意ください。
※一般的なWebのリクエスト/レスポンスやHTML、ヘッダーなどの仕様や動き・流れなどは理解しているものとして記載してます。
ログインページ解析(Chrome編)
まずは、ブラウザChrome(Microsoft Edgeなどでも可。)を使用して、ログインページの解析から始めます。
(Chrome)githubログインページの情報取得
Chromeでgithubのログインページを開きます。
ページ上で右クリック→「名前を付けて保存」より、ページのソースを保存しておきます。
(Ctrl+[s]キーでも保存できます。)
ファイル名は何でも良いです。
また、画像とかもいらないので、「ウェブページ、HTMLのみ」で保存します。

最近のログインを伴うサイトでは、CSRF(クロスサイト・リクエスト・フォージェリ)などの対策として、cookieとは別に動的な一時IDを発行しているケースがあり、その情報がだいたいログインページ上に存在していることが多いので、それらの情報を確認するためにソースを保存しておきます。
次に、ページ上で右クリック→「検証」より、ChromeのDevTool(開発者ツール)を開きます。(Ctrl+Shift+iでも開けます。)
「Network」タブを開きます。
もし、既に何か情報を取得していたら、左から2番目の「🚫」マークをクリックして、一旦情報をクリアします。
これで準備できました。
ユーザーID、パスワードを入力してログインします。
ログインすると、各ページのリクエスト・レスポンス情報がDevToolにいっぱい出てきます。
ログイン情報は通常は一番上あたりに出てきますので、一番上の情報を確認します。
(ここでは「session」を確認。)
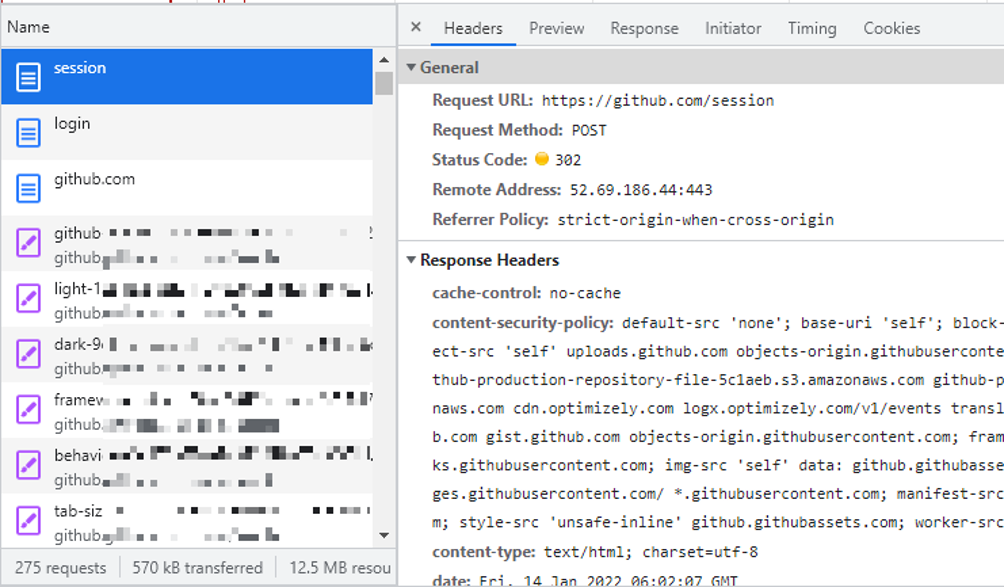
ここでは、「Header」タブのレスポンスに、
Request URL: https://github.com/session Request Method: POST Status Code: 302
とあるとおり、「/session」へPOSTして、302リダイレクトしていることがわかります。
リダイレクト先を見てみましょう。
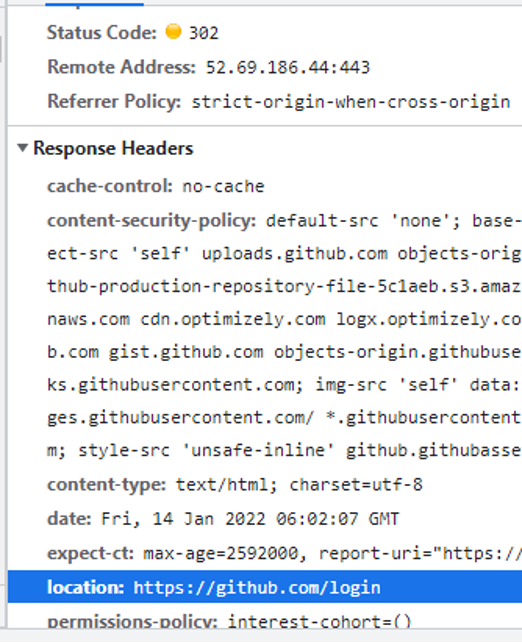
location: https://github.com/login
が出ています。
おそらくログインが成功すれば、ここへリダイレクトされるのが正解なのでしょう、と予測できます。
続いて、POSTデータを確認します。
Header内の一番下にPOSTデータが存在します。
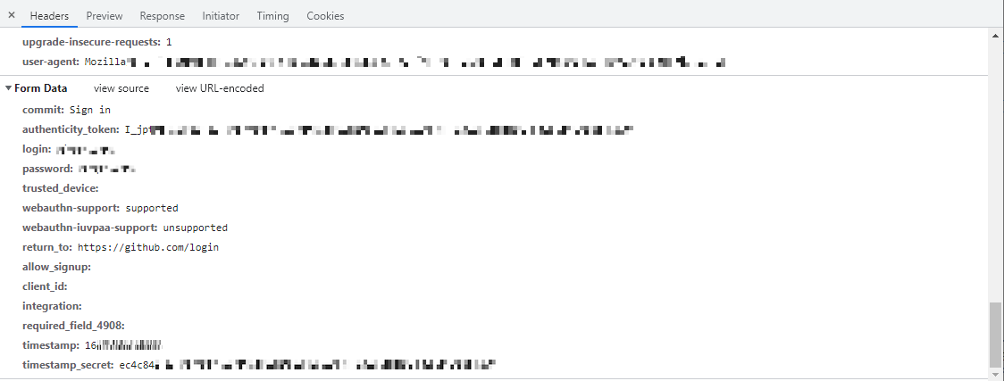
これは見やすく成形されたデータですが、一応コピーしてメモっておきましょう。
次に生データを見ます。
「view source」をクリックすると以下のような形になります。

これはほとんどそのままPOSTデータとして使えますので、こちらもコピーしてメモっておきましょう。
ログインページ解析
さて、前手順にて、ログインページを解析する準備ができましたので、解析していきたいと思います。
まず、POSTデータから、動的に取得されるデータを確認します。
commit: Sign in authenticity_token: I_jptXaxxxxxxxxxxxxxxxxxxxxxxxxxxxxx login: <ログインユーザーID> password: <パスワード> trusted_device: webauthn-support: supported webauthn-iuvpaa-support: unsupported return_to: https://github.com/login allow_signup: client_id: integration: required_field_4908: timestamp: 1642xxxxxxxxx timestamp_secret: ec4c8xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
これを見る限り、
- authenticity_token
- timestamp
- timestamp_secret
の3点が、動的に生成されたものと判断でき、それ以外は固定値なのでそのまま使えそうです。
次に、最初に保存しておいたソースをテキストで開き、上記3点のワードで検索してみます。
・・・<input type="hidden" name="authenticity_token" value="I_jptXaxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" /> ・・・
・・・<input type="hidden" name="timestamp" value="1642xxxxxxxxx" ・・・
・・・<input type="hidden" name="timestamp_secret" value="ec4c8xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" ・・・
おお。。。
全部、ソース上にありますね♪
これらを使えば、自動ログインできそう。ということが解析できました!!
次からはcurlコマンドで実行していきたいと思います。
curlでログイン編
前述の解析で、自動ログインができそうなことが判明しましたので、curlコマンドを使って実際にログイン試行してみましょう。
ログインページから動的ID取得
自動化するなら、まずは前述の確認した
- authenticity_token
- timestamp
- timestamp_secret
の情報を自動で取得できるようにします。
# ログファイルを変数定義 CookieLog=cookie.log CurlLog=Curl.log # ①ログインページのソース取得 curl -isS -c $CookieLog https://github.com/login > $CurlLog # ②各動的IDをログインページから取得 authenticity_token=$(grep -w "authenticity_token" $CurlLog | sed -e 's/^.*name="authenticity_token" value="\([^"]\+\)".*$//g') timestamp=$(grep -w "timestamp" $CurlLog | sed -e 's/^.*name="timestamp" value="\([^"]\+\)".*$//g') timestamp_secret=$(grep -w "timestamp_secret" $CurlLog | sed -e 's/^.*name="timestamp_secret" value="\([^"]\+\)".*$//g') # ③ID取得できているか確認 echo $authenticity_token echo $timestamp echo $timestamp_secret
軽~く解説。
①で、curlコマンドにて、ログインページのソースを取得しています。
ちなみに、curlのオプションは、
-i:ヘッダー情報の出力。 -s:進捗やエラーを表示しない。 -S:-sの場合もエラーは表示する。 -c:クッキー情報をファイルに保存。 -b:クッキー情報の参照。 -d:POSTデータ設定 -X:GET、POSTなどのメソッド指定(デフォルト:GET)
です。
curlのクッキーは、-c/-bオプションを使うだけで勝手に保存・参照してくれるのですごく便利です!とりあえずこのオプション付けておけば、特に意識しなくて良いんですよね~。
②で、ログインページのソースからキーワードでgrepして、sedコマンドで「value=”xxxx”」の値:xxxxだけを抜き出して変数に入れてます。
正規表現的には、ダブルクォーテーションで括られているところを、ダブルクォーテーション以外の文字列が連続している箇所のみを抜き出して置換してます。
今回、githubのサイトは、これで上手く取得できていますが、サイトによっては、ソース内に設定されているパターンが異なる場合もありますので、その都度考慮して上手く取得する必要がありますので注意が必要です。
③では、上手く取得できるか確認のためにechoで出力しています。
ここまではbashで流してみると、うまく全ての動的IDも取得できていることが確認できました。
POSTしてログイン
では、動的IDもうまく取得できたことですので、いよいよPOSTしてログインしてみます。
# ④POSTデータ生成 POSTDATA="commit=Sign+in&authenticity_token=$authenticity_token&login=<ユーザーID>&password=<パスワード>&trusted_device=&webauthn-support=supported&webauthn-iuvpaa-support=unsupported&return_to=https%3A%2F%2Fgithub.com%2Flogin&allow_signup=&client_id=&integration=&required_field_4908=×tamp=$timestamp×tamp_secret=$timestamp_secret" # ⑤POSTしてログイン試行 curl -isS -c $CookieLog -b $CookieLog -XPOST "https://github.com/session" -d "$POSTDATA"
一応解説です。
④では、前述のChromeから取得した生データを元に、動的IDのところだけ変数化($authenticity_token、$timestamp、$timestamp_secret)してそのままペタリと貼り付けただけとなります。
⑤にてID/パスワードが入ったPOSTデータを投入してログイン試行するところになります。
さて、⑤まで実行した結果は。。。。
curl -isS -c $CookieLog -b $CookieLog -XPOST "https://github.com/session" -d "$POSTDATA" HTTP/2 302 server: GitHub.com date: Fri, 14 Jan 2022 09:29:04 GMT content-type: text/html; charset=utf-8 vary: X-PJAX, X-PJAX-Container permissions-policy: interest-cohort=() location: https://github.com/login
おおおおお・・・・・!
Chromeでログインしたときと同じ、302リダイレクトが出て
location: https://github.com/login
が指定されてきました!
※ちなみに、パスワード間違ったりすると、ステータスコード:200が返ってきて、ログイン画面に戻される格好になります。
どうやらこれで、ログインは成功のようです!
試しに、ログイン後のページなどにアクセスしてみましょう。
curl -isS -c $CookieLog -b $CookieLog https://github.com/<ユーザーID>/<非公開のgitソースID>
こちらも実行後、ステータスコード:200が返ってきて、ログイン後のページが見ることができました!
※ちなみに、ログインできていない状態では、404 not foundページが返ってきてました。
これでgithubにログイン成功しましたので、このクッキーを使えば同様に、ログイン後のページの参照や更新をし放題です!!!
あとはこれらをスクリプトに記載してcronとかに登録しておけば自動化完了です。
※最後はログアウトもcurlでしておくと、安全です。
※必要に応じてステータスコードなどでエラー判定など入れるとなおGoodです。
~余談~
ちなみに、パソコンのChromeからログイン・アクセスしたグローバルIPとは違うサーバーからcrulでログインしてみたら、
curl -isS -c $CookieLog -b $CookieLog -XPOST "https://github.com/session" -d "$POSTDATA" HTTP/1.1 302 Found Server: GitHub.com Date: Fri, 14 Jan 2022 06:35:01 GMT Content-Type: text/html; charset=utf-8 Transfer-Encoding: chunked Vary: X-PJAX, X-PJAX-Container permissions-policy: interest-cohort=() Location: https://github.com/sessions/verified-device ・・・
とか出てきて、自分のメール宛てに「[GitHub] Please verify your device」としてVerification codeが送られてきました。。。
どうやら、IPアドレスが違うところからアクセスすると、別途、デバイス認証が必要なようです。。。
(そのあたりは別途対応が必要ですがここでは記載しません。あしからず。)
最後に
正直、githubをcurlで使ったことはなく、今回はこの記事用に解析して書きました(笑)。
普段は趣味のページとかで専ら使用しており、定期的に情報取得して、差分があればメールで通知とか、ページの一括更新、自動更新など、ガッツリとプログラムを組むわけでもなく、チョロっとした処理に最適で、気軽に使えるのですごく便利です。
とは言え、最近では、ロボットなどの自動ログインによる悪用を防止するための色々な措置(画像に追加パスワードを表示して入力するよう促されていたり、「私はロボットではありません」というチェックボックスが追加されていたり、などなど。)が施されていたりするので、今後、そういったサイトが多くなれば、自動化も難しくなってきてしまいますが。。。
今回はcurlコマンドを利用しましたが、bash全体で考えれば、bashには奥深い技やコマンドが多々あり、活用の幅が広がりますので、ぜひ、覚えておいて損のないシェルだと思います。
また、過去にも以下のような記事を書いてますので、良ければ参考にしてください。
ファブリカコミュニケーションズで働いてみませんか?
あったらいいな、をカタチに。人々を幸せにする革新的なサービスを、私たちと一緒に創っていくメンバーを募集しています。
ファブリカコミュニケーションズの社員は「全員がクリエイター」。アイデアの発信に社歴や部署の垣根はありません。
“自分から発信できる人に、どんどんチャンスが与えられる“そんな環境で活躍してみませんか?ご興味のある方は、以下の採用ページをご覧ください。