[2022年7月]物体検出の最新手法「YOLOv7」使ってみた
はじめまして! 新卒1年目、開発チームのkondoです。
最近、研修がひと通り終わり、案件に着手し始めました。ようやくプログラマーとしての一歩を踏み出した気持ちでこれからが楽しみです。
大学では主に物体認識・検出について勉強していましたが、入社してから物体認識の分野に全く触れていないなと思ったので、最新技術に触れてみようと思いました。今回は、2022年7月に発表された物体検出の最新手法であるYOLOv7について紹介します。
開発未経験の方でも簡単にプログラムを動かすことができるので試してみてはいかがでしょうか。
物体認識と物体検出の違い
最初に間違えやすい物体認識と物体検出の違いをはっきりさせてから本題に移りたいと思います。
物体検出と物体認識は、物体を識別するという点で類似した手法ですが、その実行方法が異なります。物体検出は、画像内の物体のインスタンスを見つけるプロセスです。ディープラーニングの場合、物体検出は物体の識別だけでなく、画像内の位置の特定が行われるという点で、物体認識の一部と言えます。
出典:MathWorks
このように画像内の複数の物体を識別するところまでが物体認識、それらの位置を特定することが物体検出となります。一般的に、物体の位置を特定したら矩形領域で囲んで、ラベルには物体の名称が書かれています。
YOLOv7とは?
YOLO(You Look Only Once)とは、推論速度が他のモデル(Mask R-CNNやSSD)よりも高速である特徴を持つ物体検出アルゴリズムの一つです。YOLOv7とはYOLOシリーズのバージョン7ということになります。
YOLOシリーズの特徴として、各バージョンによって著者が異なります。実際に、v7はv4の著者が作成しており、v6は違う著者が2022年6月に公開しています。1か月しか経ってない……。
このようにYOLOシリーズは頻繁なバージョンアップを繰り返しており、非常に人気のある物体検出アルゴリズムだといえます。
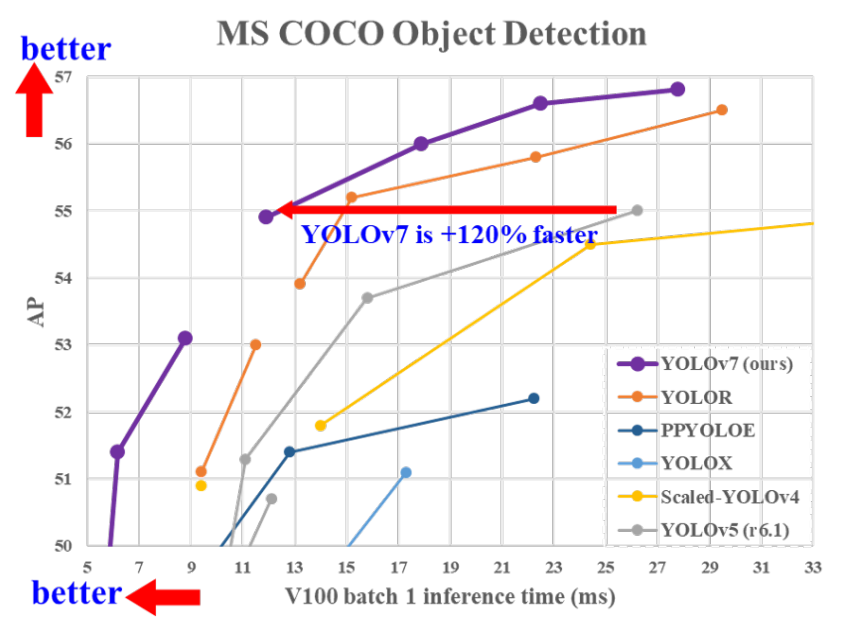
下図はgithubのREADME.meに乗っている、YOLO各シリーズの比較です。縦軸は精度、横軸は速度を表していています。ご覧の通りYOLOv7はv5と比べると120%高速化していることが分かります。
準備
①Googleアカウント作成
Google Colaboratory(以下、Google Colab)を利用するのでGoogleアカウントが必要になります。お持ちでない場合はアカウントを作成してください。
②素材となる写真や動画を準備
YOLOv7を使うために、自分で写真や動画を撮影しておきましょう。自分で画像が用意できない場合、著作権フリーの画像を検索してダウンロードしてください。
モノや人が重なっていたり、数が多いと面白い結果が出るかもしれません。
実行環境
今回はGoogle Colab環境で実行します。こちらを使用すれば、性能が低いPCでも手軽に機械学習を行うことができます。
Google Colabを利用するメリットとして、
- 手軽で簡単にすぐ始められる
- 高性能GPUが無料で使える
- 共同開発が簡単
- pythonの環境構築が楽
などがあげられます。
物体検出にはGPUがないと厳しいのですが、GPUを搭載していないPCでもGoogle Colabを使えば物体検出を行うことができます。
Intelの内臓グラフィックスで物体検出を行ったことがありますが、一瞬でPCが熱くなり、ファンの回転数がすごいことになりました。
Google Colaboratoryでの実行
Google Colabのサイトを開いてプロジェクトを作成します。プロジェクト名はなんでもよいです。
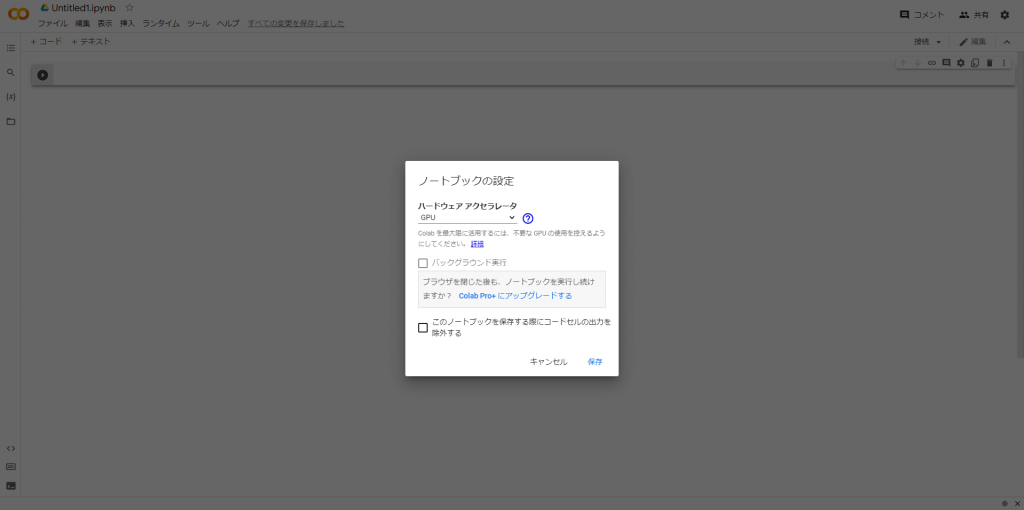
はじめに、設定を変更します。header部分に「ランタイム」項目があるのでそちらを選んで、「ランタイムのタイプを変更」を「GPU」に変更します。デフォルトではGPUを使用していないのでGoogle Colabの恩恵を最大限受けられません。
ドライブをマウントして、ディレクトリを移動します。マウントすることでGoogle Driveに保存することができます。
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive公式のGitHubからクローンします。
!git clone https://github.com/WongKinYiu/yolov7必要なライブラリをインストールします。
%cd yolov7
!pip install -r requirements.txt学習済みモデルを使った推論
今回使用する学習済みモデルを取得します。YOLOv7にはあらかじめ、学習済みモデルがいくつか用意されています。学習済みモデルの比較は公式のgithubの掲載されているのでここでは省略します。
ここでは推論結果が一番よかった「yolov7-e6e.pt」を使用することにします。
!wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-e6e.ptまずはサンプル画像として用意されている写真で実行してみましょう。inference/images配下を見るとサンプル画像が6枚用意されています。
以下のコードを実行しましょう!
!python detect.py --source inference/images/ --weights yolov7-e6e.pt --conf 0.25 --img-size 1280 --device 0–sourceオプションではディレクトリ内にあるすべての画像を指定しています。「実行するのは一枚でいいんだ!」という方は画像ファイルも指定してあげましょう。
サンプル画像「horse.jpg」の実行結果です。高い認識率で検出することができています。

任意の画像で実行してみる
サンプル画像を実行した後は、事前準備で用意した画像で実行してみましょう 。
inference/images/に用意した画像をアップロードして実行します。画像ファイル名は「fabrica.jpg」としています。
!python detect.py --source inference/images/fabrica.jpg --weights yolov7-e6e.pt --conf 0.25 --img-size 1280 --device 0サンプル画像にちなんで、馬の画像で実行してみました。
奥のプランターがたくさん検出されており、白馬を引いている厩務員は、馬の首で上半身がほとんど隠れているのにも関わらず検出することができています。

任意の動画で実行してみる
任意の画像で実行した後は、動画で実行してみましょう。
わたしは、本社の前にある大きな交差点で撮影しました。実際には撮影した動画を実行していますが、こちらには実行結果を画像で切り抜いて載せています。
任意の画像で実行してみたときと同様に、inference/images/に用意した画像をアップロードして実行します。動画ファイル名は「fabrica.mp4」としています。
※拡張子が.MOVの場合でも動作します
!python detect.py --source inference/images/fabrica.mp4 --weights yolov7-e6e.pt --conf 0.25 --img-size 1280 --device 0うまく認識することができました。車の領域の大部分が重なっていても検出できています。すごい!
ここまで出来たら、YOLOv7のチュートリアルは完了です。お疲れ様でした!


まとめ
最後までご覧いただきありがとうございました。
今回は物体検出の最新技術であるYOLOv7について紹介しました。ここでの推論では学習済みモデルを使用した一般的な物体(人や車など)を検出しましたが、自作の学習モデルを作成し使用することで特定の物体(個人や車種)を検出することもできます。この記事で物体検出を体験してみて興味が湧いた方は、ぜひチャレンジしてみてください。
物体検出は、顔認識や、自動運転、がんの病変領域検知など多岐にわたって応用されています。この記事を通して物体検出が様々な業界で利用されていることを、より身近に感じていただけたら幸いです。
ファブリカコミュニケーションズで働いてみませんか?
あったらいいな、をカタチに。人々を幸せにする革新的なサービスを、私たちと一緒に創っていくメンバーを募集しています。
ファブリカコミュニケーションズの社員は「全員がクリエイター」。アイデアの発信に社歴や部署の垣根はありません。
“自分から発信できる人に、どんどんチャンスが与えられる“そんな環境で活躍してみませんか?ご興味のある方は、以下の採用ページをご覧ください。